How about some QC on Rosetta WU's?
Message boards : Number crunching : How about some QC on Rosetta WU's?
| Author | Message |
|---|---|
|
BadThad Send message Joined: 8 Nov 05 Posts: 30 Credit: 71,834,523 RAC: 0 |
The "max time exceeded" or "stuck at 1%" or "wu hosed for whatever reason" is getting out of control with this project. I have too many machines to waste time babysitting them every day. I've been running DC projects for many years and this is the only project I've seen send out masses of bad wu's. Get some QC on those wu's....PLEASE. One sure way to kill a project for people that run lot's of computers is to force us to babysit the dang client. I've had countless hours of CPU time completely wasted away with Rosetta, IT MUST STOP! |
 Hoelder1in Hoelder1inSend message Joined: 30 Sep 05 Posts: 169 Credit: 3,915,947 RAC: 0 |
With all the ongoing complaints about WU errors, perhaps it would help if the project stated the total error rate they see in the database to put things into perspective. Judging from the ~2000 WUs I have crunched, I would guess that it must be considerably below 1% (one failed WU among 184 on my current results page). It might also be of interest to see how the error rate varies across different hosts/OS type/BOINC versions... |
|
Paul D. Buck Send message Joined: 17 Sep 05 Posts: 815 Credit: 1,812,737 RAC: 0 |
Paul's current opinion on the current state of the projects. Your mileage may vary ... but, basically none of the projects are without problems: SETI@Home in the last couple months has sent out several batches of 20,000 or so work units that were all bad. SDG is having problems with some participant's work and reported time, venue, and daily quotas. Also they have regular issues with work available but committed to other platforms. Predictor@Home has had, off and on, problems with a pop-up dialog (the science application has not changed since this was first reported in August of 2005), work that over-runs time. Also they have regular issues with work available but committed to other platforms. CPDN seems to be having a higher than normal failure rate with work issued against Sulfur 4.22; I have had at least one computer that has done a fiar number of Slab and Sulfur work units but has not been able to start a new one up. Just as a note, most of them also failed with a second issue to another participant. Einstein@Home had an issue with work running too fast that many participants were running out, since fixed with an increase in daily quota. SIMAP is having some problems with participants on dial up because of the size of the work download/upload sizes (I have yet to look into actual numbers on my systems so I do not know how bad this problem is). PrimeGrid is having connectivity problems (non-comercial connection to the Internet) WCG has an acute case of using United Devices technology making them unsuitable for some participants along with an only partially complient BOINC infrastructure (though they are adding features, the last was team stat exports - but still missing are Work Unit and Result pages) also reported by some that there seems to be a bug in the way preferences are handled with WCG at times over-ruling other settings. There may be other problems but I do not monitor the WCG boards as they are non-BOINC and I get lost ... The bottom line, no project is without issues, most work fairly well, but at this time, if you cannot monitor your computers then, in my opinion this renders Predictor@Home and Rosetta@Home unsuitable for you. Rosetta@Home is working hard, and based on my experience the 1% problem incidence is lower now than when it first surfaced. I only had one time over-run so, not sure about that one. Disclaimer: For various reasons I am not running the following projects: SETI@Home, Rosetta@Home, Predictor@Home, SZTAKI Desktop Grid, and PrimeGrid. This is primarily because my main interest is CPDN, Einstein@Home, and LHC@Home; WCG Pirates@Home, and SIMAP@Home are "live" because I am trying to get their lifetime total credit values to certain positions. |
|
David Baker Volunteer moderator Project administrator Project developer Project scientist Send message Joined: 17 Sep 05 Posts: 705 Credit: 559,847 RAC: 0 |
With all the ongoing complaints about WU errors, perhaps it would help if the project stated the total error rate they see in the database to put things into perspective. Judging from the ~2000 WUs I have crunched, I would guess that it must be considerably below 1% (one failed WU among 184 on my current results page). It might also be of interest to see how the error rate varies across different hosts/OS type/BOINC versions... In fact, the overall error rate is pretty low. with the cpu time limit problem fixed, it appears that a relatively small fraction of users are having the majority of the wu probems--we wish we understood what was causing these! |
|
Scribe Send message Joined: 2 Nov 05 Posts: 284 Credit: 157,359 RAC: 0 |
Paul's current opinion on the current state of the projects. Your mileage may vary ... WCG has an acute case of using United Devices technology making them unsuitable for some participants along with an only partially complient BOINC infrastructure (though they are adding features, the last was team stat exports - but still missing are Work Unit and Result pages)........ The results page has been there for at least 3 days now.......  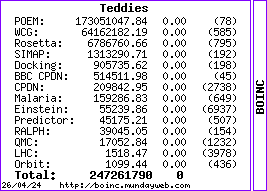
|
|
Ib Rasmussen Send message Joined: 27 Sep 05 Posts: 16 Credit: 211,416 RAC: 0 |
Admittedly all the projects have their problems, but I agree with the orignal poster, that Rosetta has needed more operator intervention - or babysitting, if you like - than any of the other of the big boinc projects, I participate in. That why I only run r@h on the few machine I have daily access to. /Ib |
|
Paul D. Buck Send message Joined: 17 Sep 05 Posts: 815 Credit: 1,812,737 RAC: 0 |
In fact, the overall error rate is pretty low. with the cpu time limit problem fixed, it appears that a relatively small fraction of users are having the majority of the wu probems--we wish we understood what was causing these! Have you considered re-issuing some of those work units to other participants? All of the stuck at 1% that I had restarted and ran to completion which, as I understand it, means that the model did not run with one RND seed but did with another. Are the seeds saved? If not that should be on the list of things to add to the std out recorded by the WU and returned when reported. I am guessing you looked for commonality between the systems with the highest error rates for common factors. Have you considered that it could be a cross-project issue? It only happens if the participant also runs CPDN for example ... Just thinking out loud ... |
|
[B@H] Ray Send message Joined: 20 Sep 05 Posts: 118 Credit: 100,251 RAC: 0 |
With all the ongoing complaints about WU errors, perhaps it would help if the project stated the total error rate they see in the database to put things into perspective. Judging from the ~2000 WUs I have crunched, I would guess that it must be considerably below 1% (one failed WU among 184 on my current results page). It might also be of interest to see how the error rate varies across different hosts/OS type/BOINC versions... I have to agree with you, I have only had 1 bad unit since I started in Sept. 05, aborted that at about 10 hours at 1%. Would have timed out on it's own if I let it run. And at one time when they had a batch of bad units I had a bunch crash at about 1 secound just like everyone else but the total errror rate would be less than .5% which is not bad. I have to admit that for a short while I was aborting units that were returned by other systems 2 to 4 times as bad, but than I ran some of those and had no problems with them. Guess that some systems run these better than others, but give more problems on other programs. Will be fireing up an old K6 in a while, wonder if that will run Rosetta? Think not, can onlt get 192 Megs ram in it without buying more. Cheers Ray System 1 P4 2.4 gig, 533 fsb, 1024 meg, 512K L2, Win XP, BOINC 4.68 System 2 Celeron 2.93 gig, 533 fsb, 1024 megs, 256K L2, Win XP, BOINC 4.68  Pizza@Home Rays Place Rays place Forums |
|
yoner Send message Joined: 17 Sep 05 Posts: 10 Credit: 2,581,874 RAC: 0 |
As for resources needed with this project, I actually have an old Dell dual PII-233 running with 128 MB ram (running two threads of rosetta), and am getting fairly decent results from it. The computer sits in the corner and crunches units and streams my MP3 collection to my other computer. Your K6 may do better than you think! 
|
|
BadThad Send message Joined: 8 Nov 05 Posts: 30 Credit: 71,834,523 RAC: 0 |
With all the ongoing complaints about WU errors, perhaps it would help if the project stated the total error rate they see in the database to put things into perspective. Judging from the ~2000 WUs I have crunched, I would guess that it must be considerably below 1% (one failed WU among 184 on my current results page). It might also be of interest to see how the error rate varies across different hosts/OS type/BOINC versions... I think there's a small fraction of users with wu problems because I received all the bad ones on the 30 systems I run Rosetta on. LMAO |
|
keputnam Send message Joined: 18 Sep 05 Posts: 24 Credit: 2,134,864 RAC: 0 |
[quote Will be fireing up an old K6 in a while, wonder if that will run Rosetta? Think not, can onlt get 192 Megs ram in it without buying more. [/quote] Should be fine. I've got a PII/400/192MB/Win98se that runs Rosetta with no problems (well, very few problems ;-) )  
|
|
Mike Gelvin Send message Joined: 7 Oct 05 Posts: 65 Credit: 10,612,039 RAC: 0 |

|
|
Dimitris Hatzopoulos Send message Joined: 5 Jan 06 Posts: 336 Credit: 80,939 RAC: 0 |
|
|
Mike Gelvin Send message Joined: 7 Oct 05 Posts: 65 Credit: 10,612,039 RAC: 0 |
|
Message boards :
Number crunching :
How about some QC on Rosetta WU's?

©2026 University of Washington
https://www.bakerlab.org